首先十分感谢祥哥的建议:
一般刚接触web,会多建议走广度,了解web技术的全貌,spring,缓存,消息队列,分布式等等。
但是深度也不是不没用,毕竟深度决定潜力。如果想往深度走,例如把spring吃透,也是很不错的。
不过从职场的角度,可能开始走广度会更有利于以后发展。
深度可以在某个时间段进行,例如你做到架构,就需要沉淀技术深度的东西。
项目中常使用到的技术(基于SSM)
- 分布式技术:Dubbo,Zookeeper
- 数据库存储:MySQL,Redis,MongoDB(少用到)
- 消息服务:ActiveMq
- 文件存储FTP,OSS
下面简单对它们进行了解,了解它们是什么,能有什么作用
Dubbo和Zookeeper
Dubbo是Alibaba的开源框架,最大的特点是按照分层的方式来架构,使用这种技术可以使各个层之间解耦。
Dubbo采用的是一种简单的模型,要么是提供者提供服务,要么是消费者消费服务,可以抽象出服务提供者(Provider)和服务消费者(Consumer)。
下图是Dubbo框架模型:一共有十层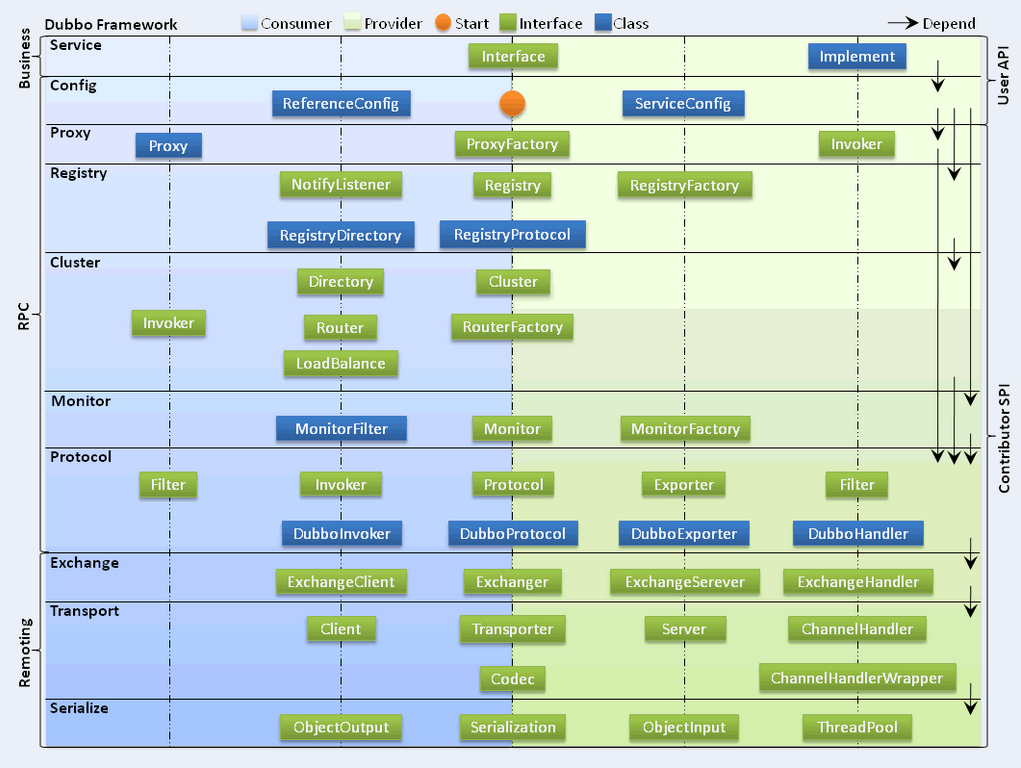
Dubbo作为一个分布式服务框架,主要具有如下几个核心的要点:
- 服务定义:
服务是围绕服务提供方和服务消费方的,服务提供方实现服务,而服务消费方调用服务。 - 服务注册
对于服务提供方,它需要发布服务,而且由于应用系统的复杂性,服务的数量、类型也不断膨胀;对于服务消费方,它最关心如何获取到它所需要的服务,而面对复杂的应用系统,需要管理大量的服务调用。而且,对于服务提供方和服务消费方来说,他们还有可能兼具这两种角色,即既需要提供服务,有需要消费服务。
通过将服务统一管理起来,可以有效地优化内部应用对服务发布/使用的流程和管理。服务注册中心可以通过特定协议来完成服务对外的统一。
Dubbo推荐使用Zookeeper注册中心 - 服务监控
无论是服务提供方,还是服务消费方,他们都需要对服务调用的实际状态进行有效的监控,从而改进服务质量。 - 服务调用
最后简单介绍一下Dubbo基于RPC层,服务提供方和服务消费方之间的关系
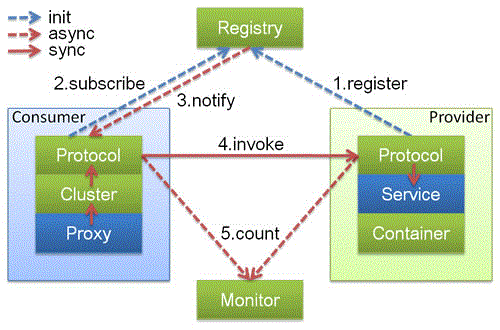
上图中蓝色的表示与业务有交互,绿色的表示只对Dubbo内部交互。上述图所描述的调用流程如下:
1. 服务提供方发布服务到服务注册中心;
2. 服务消费方从服务注册中心订阅服务;
3. 服务消费方调用已经注册的可用服务。
更多调用流程请看这篇文章:Dubbo文章参考
Zookeeper
用来注册服务和进行负载均衡,哪一个服务由哪一个机器来提供必须让调用者知道。
zookeeper通过心跳机制可以检测挂掉的机器并将挂掉机器的ip和服务对应关系从列表中删除。
通过添加新的机器向zookeeper注册服务,服务的提供者增加,能够服务的客户就能增加。
Zookeeper与Dubbo的关系
Dubbo的将注册中心进行抽象,是得它可以外接不同的存储媒介给注册中心提供服务,有ZooKeeper,Memcached,Redis等。
引入了ZooKeeper作为存储媒介,也就把ZooKeeper的特性引进来。首先是负载均衡,单注册中心的承载能力是有限的,在流量达到一定程度的时候就需要分流,负载均衡就是为了分流而存在的,一个ZooKeeper群配合相应的Web应用就可以很容易达到负载均衡;资源同步,单单有负载均衡还不够,节点之间的数据和资源需要同步,ZooKeeper集群就天然具备有这样的功能;命名服务,将树状结构用于维护全局的服务地址列表,服务提供者在启动的时候,向ZK上的指定节点/dubbo/${serviceName}/providers目录下写入自己的URL地址,这个操作就完成了服务的发布。其他特性还有Mast选举,分布式锁等。
Zookeeper基础概念了解请看这篇文章: zookeeper基础了解
Redis
Redis简介(中文网站):
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
Redis 优势:
- 速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
- 支持丰富数据类型,支持string,list,set,sorted set,hash
- 支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行。
- 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
在Java中使用的是Jedis,可以在Redis官网查看如何使用,常用的套路是使用MySQL存储需要长久存放的数据,使用Redis进行缓存,设置一个过期时间,不能让Redis存储太多,不然内存占用会升高。
ActiveMq
首先介绍一下MQ:
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过写和检索出入列队的针对应用程序的数据(消息)来通信,而无需专用连接来链接它们。消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。
MQ特点:
MQ的消费-生产者模型的一个典型的代表,一端往消息队列中不断的写入消息,而另一端则可以读取或者订阅队列中的消息。MQ和JMS类似,但不同的是JMS是SUN Java消息中间件服务的一个标准和API定义,而MQ则是遵循了AMQP协议的具体实现和产品。
接着介绍JMS(Java Message Service):
JMS是Java平台上有关面向消息中间件(MOM)的技术规范,它便于消息系统中的Java应用程序进行消息交换,并且通过提供标准的产生、发送、接收消息的接口简化企业应用的开发,翻译为Java消息服务。
ActiveMq优点:
是一个快速的开源消息组件(框架),支持集群,同等网络,自动检测,TCP,SSL,广播,持久化,XA,和J2EE1.4容器无缝结合,并且支持轻量级容器和大多数跨语言客户端上的Java虚拟机。消息异步接受,减少软件多系统集成的耦合度。消息可靠接收,确保消息在中间件可靠保存,多个消息也可以组成原子事务。
个人理解是通过发送消息到队列中,不直接调用服务处理,而是配置处理器进行事件的处理,异步处理消息用来进行应用间的解耦,节省了服务器的请求响应时间,从而提高了系统的吞吐量,最后确保最终一致性。
关于ActiveMq的了解可以看这篇文章:ActiveMq基础了解
文件存储FTP和OSS
网络操作中,有很多场景下涉及到文件的操作,这时就需要使用到ftp和oss。
FTP:全称(File Transfer Protocol)
用于在网络上的控制文件的双向传输。我们经常使用到的是上传(upload)和下载(download)。
在后端中使用,需要写好配置文件,在代码中也需要通过连接ftp服务器,将文件转成输入流上传到ftp服务器,拿到ftp服务器的文件地址,就能将文件下载下来。
OSS:全称(Object Storage Service)
常用的是阿里的oss,使用它有以下好处:
- OSS服务可用性不低于99.9%,规模自动扩展,数据持久性不低于99.99999999%,数据自动多重冗余备份。
- OSS提供企业级多层次安全防护和防DDoS攻击,自动黑洞清洗。OSS实行多用户资源隔离机制,支持异地容灾机制。
- OSS还提供多种鉴权和授权机制及白名单、防盗链、主子账号功能。
- OSS性价比高,多线BGP骨干网络,无带宽限制,上行流量免费,无需运维人员与托管费用,0成本运维。
- OSS还提供图片处理、音视频转码、内容加速分发、鉴黄服务、归档服务等多种数据增值服务,并在不断丰富着。
基于以上优点,学习使用OSS也是很有必要的,官方文档 的介绍很详细了。