
[TOC]
前言
既然我们 Spring 辛辛苦苦将 bean 进行了注册,当然需要拿出来进行使用,在使用之前还需要经过一个步骤,就是 bean 的加载。
在第一篇笔记提到了,完成 bean 注册到 beanDefinitionMap 注册表后,还调用了很多后处理器的方法,其中有一个方法 finishBeanFactoryInitialization(),注释上面写着 Instantiate all remaining (non-lazy-init) singletons,意味着非延迟加载的类,将在这一步实例化,完成类的加载。
而我们使用到 context.getBean("beanName")方法,如果对应的 bean 是非延迟加载的,那么直接就能拿出来进行使用,而延迟加载的 bean 就需要上面的步骤进行类的加载,加载完之后才能进行使用~
下面一起来看下这两个步骤中, bean 是如何进行加载的。
时序图
我们的代码分析都是围绕着这个方法,请同学们提前定位好位置:
org.springframework.beans.factory.support.AbstractBeanFactory#doGetBean
这个 bean 加载的代码量是有点多的,已经超过 100 行,所以整理了时序图,希望能对加载流程有个清晰的概览:
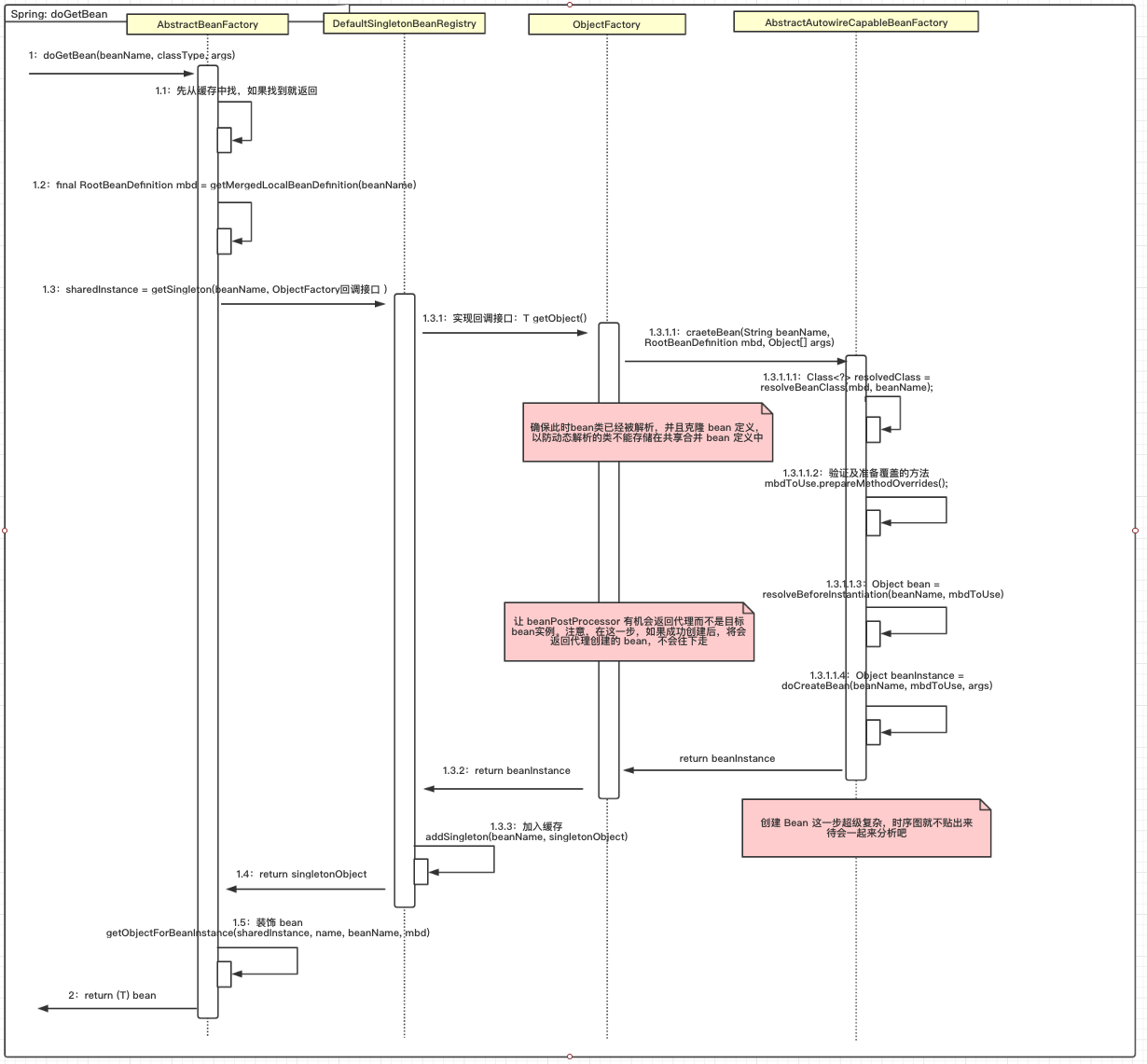
这个时序图介绍了 bean 加载的大体流程,还有很多细节没在图中进行展示。我们先对整体流程有个了解,然后跟着代码一起深入分析吧。
代码分析
再提示一下:由于代码量很多,每次贴大段代码看起来会比较吃力,所以展示的是我认为的关键代码,下载项目看完整注释,跟着源码一起分析~
FactoryBean 的使用
在分析加载流程之前,有个前置概念要了解下,在一般情况下,Spring 是通过反射机制利用 bean 的 class 属性指定实现类来实例化 bean。
引用书本:
在某些情况下,实例化
bean比较复杂,例如有多个参数的情况下,传统方式需要在配置文件中,写很多配置信息,显得不太灵活。在这种情况下,可以使用Spring提供的FactoryBean接口,用户可以通过实现该接口定制实例化bean的逻辑。
FactoryBean 接口定义了三个方法:
1 | public interface FactoryBean<T> { |
主要讲下用法吧:
当配置文件中的
<bean>的class属性实现类是FactoryBean时,通过getBean()方法返回的不是FactoryBean本身,而是FactoryBean#getObject()方法返回的对象。
使用 demo 代码请看下图:

扩展 FactoryBean 之后,需要重载图中的两个方法,通过泛型约定返回的类型。在重载的方法中,进行自己个性化的处理。
在启动类 Demo,通过上下文获取类的方法 context.getBean("beanName"),使用区别是 beanName 是否使用 & 前缀,如果有没有 & 前缀,识别到的是 FactoryBean.getObject 返回的 car 类型,如果带上 & 前缀,那么将会返回 FactoryBean 类型的类。
验证和学习书中的概念,最快的方式是运行一遍示例代码,看输出结果是否符合预期,所以参考书中的例子,自己手打代码,看最后的输出结果,发现与书中说的一致,同时也加深了对 FactoryBean 的了解。
为什么要先讲 BeanFactory 这个概念呢?
从时序图看,在 1.5 那个步骤,调用了方法:
org.springframework.beans.factory.support.AbstractBeanFactory#getObjectForBeanInstance
在这一步中,会判断 sharedInstance 类型,如果属于 FactoryBean,将会调用用户自定义 FactoryBean 的 getObject() 方法进行 bean 初始化。
实例化的真正类型是 getObjectType() 方法定义的类型,不是 FactoryBean 原来本身的类型。最终在容器中注册的是 getObject() 返回的 bean。
提前讲了这个概念,希望大家在最后一步时不会对这个有所迷惑。
从缓存中获取单例 bean
1 | // Eagerly check singleton cache for manually registered singletons. |
单例模式在代码设计中经常用到,在 Spring 中,同一个容器的单例只会被创建一次,后续再获取 bean 直接从单例缓存 singletonObjects 中进行获取。
而且因为单例缓存是公共变量,所以对它进行操作的时候,都进行了加锁操作,避免了多线程并发修改或读取的覆盖操作。
还有这里有个 earlySingletonObjects 变量,它也是单例缓存,也是用来保存 beanName 和 创建 bean 实例之间的关系。
与 singletonFactories 不同的是,当一个单例 bean 被放入到这 early 单例缓存后,就要从 singletonFactories 中移除,两者是互斥的,主要用来解决循环依赖的问题。(循环依赖下一篇再详细讲吧)
从 bean 的实例中获取对象
在 getBean 方法中,getObjectForBeanInstance 是个高频方法,在单例缓存中获得 bean 还是 根据不同 scope 策略加载 bean,都有这个方法的出现,所以结合刚才说的 BeanFactory 概念,一起来看下这个方法做了什么。
org.springframework.beans.factory.support.AbstractBeanFactory#getObjectForBeanInstance
1 | // 返回对应的实例,有时候存在诸如 BeanFactory 的情况并不是直接返回实例本身 |
具体方法实现,搜索 注释 4.6 看代码中的注释吧:
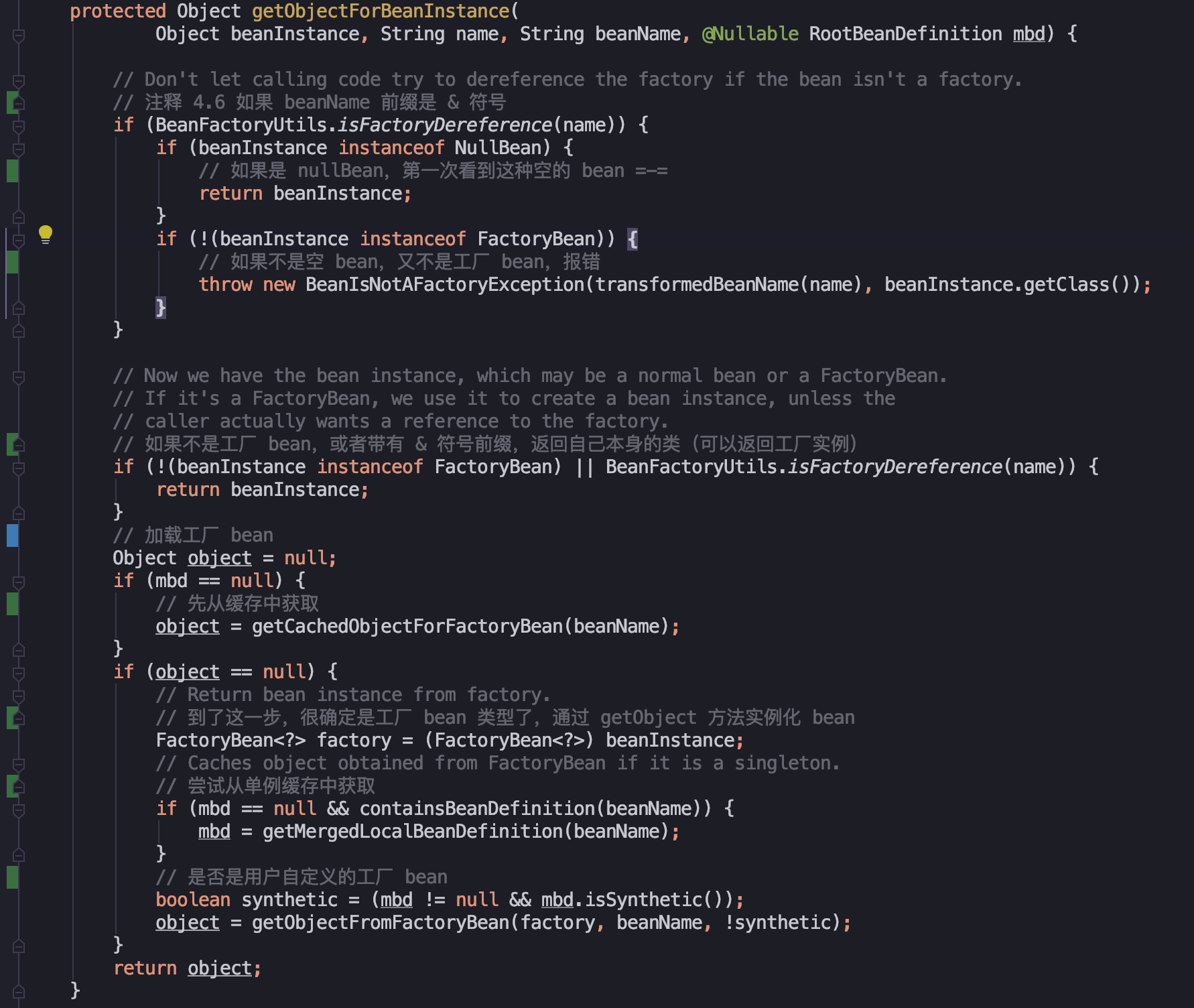
交代一下这个方法的流程:
- 验证
bean类型:判断是否是工厂bean - 对非
FactoryBean不做处理 - 对
bean进行转换 - 处理
FactoryBean类型:委托给getObjectFromFactoryBean方法进行处理。
在这个方法中,对工厂 bean 有特殊处理,处理方法跟上面提到的 FactoryBean 使用一样,最终获取的是 FactoryBean.getObject() 方法返回的类型。
对于第四个步骤,委托给 getObjectFromFactoryBean 方法进行处理不深入分析,但里面有三个方法值得一说:
1 | // 单例操作,前置操作 |
代码中在类的加载时,有前置操作和后置操作,之前在第一篇笔记看过,很多前置和后置操作都是空方法,等用户自定义扩展用的。
但在这里的不是空方法,在两个方法是用来保存和移除类加载的状态,是用来对循环依赖进行检测的。
同时,这两个方法在不同 scope 加载 bean 时也有使用到,也是个高频方法。
1 | try { |
这是一个执行后处理的方法,我接触的不多,先记下概念:
Spring 获取 bean 的规则中有一条:尽可能保证所有 bean 初始化后都会调用注册的 BeanPostProcessor 的 postProcessAfterInitialization 方法进行处理。在实际开发中,可以针对这个特性进行扩展。
获取单例
现在来到时序图中的 1.3 步骤:
1 | // Create bean instance. 创建 bean 实例 |
来看 getSingleton 方法做了什么:
1 | public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) { |
来梳理一下流程:
- 检查缓存是否已经加载过
- 没有加载,记录
beanName的加载状态 - 调用回调接口,实例化
bean - 加载单例后的处理方法调用:这一步就是移除加载状态
- 将结果记录到缓存并删除加载
bean过程中所记录到的各种辅助状态
对于第二步和第四步,在前面已经提到,用来记录 bean 的加载状态,是用来对 循环依赖 进行检测的,这里先略过不说。
关键的方法在于第三步,调用了 ObjectFactory 的 getObject() 方法,实际回调接口实现的是 createBean() 方法,需要往下了解,探秘 createBean()。
准备创建 bean
对于书中,有句话说的很到位:
在
Spring源码中,一个真正干活的函数其实是以do开头的,比如doGetBean、doGEtObjectFromFactoryBean,而入口函数,比如getObjectFromFactoryBean,其实是从全局角度去做统筹工作。
有了这个概念后,看之后的 Spring 源码,都知道这个套路,在入口函数了解整体流程,然后重点关注 do 开头的干活方法。
按照这种套路,我们来看这个入口方法 createBean()
org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#createBean(java.lang.String, org.springframework.beans.factory.support.RootBeanDefinition, java.lang.Object[])
1 | protected Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) { |
先来总结这个流程:
- 根据设置的 class 属性或者根据 className 来解析 Class
- 验证及准备覆盖的方法
这个方法是用来处理以下两个配置的:我们在解析默认标签时,会识别lookup-method和replaced-method属性,然后这两个配置的加载将会统一存放在beanDefinition中的methodOverrides属性里。 - 应用初始化前的后处理器,解析指定 bean 是否存在初始化前的短路操作
- 创建 bean
下面来讲下这几个主要步骤
处理 Override 属性
1 | public void prepareMethodOverrides() throws BeanDefinitionValidationException { |
可以看到,获取类的重载方法列表,然后遍历,一个一个进行处理。具体处理的是 lookup-method 和 replaced-method 属性,这个步骤解析的配置将会存入 beanDefinition 中的 methodOverrides 属性里,是为了待会实例化做准备。
如果 bean 在实例化时,监测到 methodOverrides 属性,会动态地位当前 bean 生成代理,使用对应的拦截器为 bean 做增强处理。
(我是不推荐在业务代码中使用这种方式,定位问题和调用都太麻烦,一不小心就会弄错=-=)
实例化前的前置处理
1 | // 让 beanPostProcessor 有机会返回代理而不是目标bean实例。 |
在 doCreateBean 方法前,有一个短路操作,如果后处理器成功,将会返回代理的 bean。
在 resolveBeforeInstantiation 方法中,在确保 bean 信息已经被解析完成,执行了两个关键方法,从注释中看到,一个是前置拦截器的操作,另一个就是后置拦截器的操作。
如果第一个前置拦截器实例化成功,就已经将单例 bean 放入缓存中,它不会再经历普通 bean 的创建过程,没有机会进行后处理器的调用,所以在这里的第二个步骤,就是为了这个 bean 也能应用后处理器的 postProcessAfterInitialization 方法。
创建 bean
终于到了关键的干活方法:doGetBean。在通过上一个方法校验,没有特定的前置处理,所以它是一个普通 bean, 常规 bean 进行创建在 doGetBean 方法中完成。
1 | protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args) { |
看到这么长的代码,感觉有点头晕,所以先来梳理这个方法的流程:
- 如果加载的 bean 是单例,要清除缓存
- 实例化 bean,将 BeanDifinition 转化成 BeanWrapper
- 后处理器修改合并后的 bean 定义:
bean 合并后的处理,Autowired 注解正式通过此方法实现诸如类型的预解析 - 依赖处理
- 属性填充:将所有属性填充到 bean 的实例中
- 循环依赖检查
- 注册 DisposableBean:这一步是用来处理 destroy-method 属性,在这一步注册,以便在销毁对象时调用。
- 完成创建并返回。
从上面流程可以看出,这个方法做了很多事情,以至于代码超过了 100 多行,给人的阅读体验差,所以尽量还是拆分小方法,在入口方法尽量简洁,说明做的事情,具体在小方法中完成。
因为这个创建过程的代码很多和复杂,我挑重点来理解和学习,详细的还有待深入学习:
创建 bean 的实例
在上面第二个步骤,做的是实例化 bean,然后返回 BeanWrapper
1 | protected BeanWrapper createBeanInstance(String beanName, RootBeanDefinition mbd, Object[] args) { |
大致介绍功能:
- 如果存在工厂方法则使用工厂方法进行初始化
- 一个类有多个构造函数,每个构造函数都有不同的参数,所以需要根据参数锁定构造函数进行 bean 的实例化:
在这一步我是真心服,为了匹配到特定的构造函数,下了很大的功夫,感兴趣的可以定位到这个函数观看org.springframework.beans.factory.support.ConstructorResolver.autowireConstructor - 如果即不存在工厂方法,也不存在带有参数的构造函数,会使用默认的构造函数进行 bean 的实例化
在这个流程中,通过两种方式,一种是工厂方法,另一种就是构造函数,将传进来的 RootBeanDefinition 中的配置二选一生成 bean 实例
具体的不往下跟踪,来看下一个步骤
处理循环依赖
1 | // 是否需要提前曝光,用来解决循环依赖时使用 |
关键方法是 addSingletonFactory,完成的作用:在 bean 初始化完成前将创建实例的 ObjectFactory 加入单例工厂
一开始就讲过, ObjectFactory 是创建对象时使用的工厂。在对象实例化时,会判断自己依赖的对象是否已经创建好了,判断的依据是查看依赖对象的 ObjectFactory 是否在单例缓存中,如果没有创建将会先创建依赖的对象,然后将 ObjectFactory 放入单例缓存。
这时如果有循环依赖,需要提前对它进行暴露,让依赖方找到并正常实例化。
循环依赖解决方案在下一篇再细讲吧。
属性注入
这也是个高频方法,在初始化的时候要对属性 property 进行注入,贴一些代码片段:
populateBean(beanName, mbd, instanceWrapper);
1 | protected void populateBean(String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) { |
由于代码太长,感兴趣的小伙伴定位到 注释 4.11 位置查看吧
介绍一下处理流程:
- 调用
InstantiationAwareBeanPostProcessor处理器的postProcessAfterInstantiation方法,判断控制程序是否继续进行属性填充 - 根据注入类型(
byName/byType),提取依赖的bean,统一存入PropertyValues中 - 判断是否需要进行
BeanPostProcessor和 依赖检查:
- 如果有后处理器,将会应用
InstantiationAwareBeanPostProcessor处理器的postProcessProperties方法,对属性获取完毕填充前,对属性进行再次处理。 - 使用
checkDependencies方法来进行依赖检查
- 将所有解析到的
PropertyValues中的属性填充至BeanWrapper中。
在这个方法中,根据不同的注入类型进行属性填充,然后调用后处理器进行处理,最终将属性应用到 bean 中。
这里也不细说,继续往下走,看下一个方法
初始化 bean
在配置文件中,在使用 <bean> 标签时,使用到了 init-method 属性,这个属性的作用就是在这个地方使用的:bean 实例化前,调用 init-method 指定的方法来根据用户业务进行相应的实例化。来看下入口方法 initializeBean:
1 | // 调用初始化方法,例如 init-method |
这个方法主要是用来进行我们设定的初始化方法的调用,不过在方法内部,还做了其它操作,所以一起来讲下流程:
1、激活 Aware 方法
Spring 中提供了一些 Aware 接口,实现了这个接口的 bean,在被初始化之后,可以取得一些相对应的资源,例如 BeanFactoryAware,在初始化后, Spring 容器将会注入 BeanFactory 的实例。所以如果需要获取这些资源,请引用 Aware 接口。
2、执行后处理器
相信这个大家已经不陌生了,我们可以在诸如 PostProcessor 等后处理器里面自定义,实现修改和扩展。例如 BeanPostProcessor 类中有 postProcessBeforeInitialization 和 postProcessAfterInitialization,可以对 bean 加载前后进行逻辑扩展,可以将它理解成切面 AOP 的思想。
3、激活自定义的 init 方法
这个方法用途很明显,就是找到用户自定义的构造函数,然后调用它。要注意的是,如果 bean 是 InitializingBean 类型话,需要调用 afterPropertiesSet 方法。
执行顺序是先 afterPropertiesSet,接着才是 init-method 定义的方法。
注册 disposableBean
这是 Spring 提供销毁方法的扩展入口,Spring 爸爸将我们能考虑和想扩展的口子都给预留好。除了通过 destroy-method 属性配置销毁方法外,还可以注册后处理器 DestructionAwareBeanPostProcessor 来统一处理 bean 的销毁方法:
1 | protected void registerDisposableBeanIfNecessary(String beanName, Object bean, RootBeanDefinition mbd) { |
这里就是往不同的 scope 下, 进行 disposableBean 的注册。
总结
本篇笔记总结了类加载的过程,结合时序图和代码分析,希望对它能有一个更深的了解。
同时对代码编写也有一点感触:
- 不要写过长的方法,尽量拆分成小方法,清晰意图
从一开始看Spring源码的时候,就惊叹于它代码的整洁和逻辑清晰,入口方法展示也要做的事情,然后工作具体逻辑细分,体现了代码设计者的高超设计,所以在看到有几个方法超过 100 行,心中小小吐槽了一下,看来我跟大佬们写的代码也有共同点,可以进行优化~ - 要在关键地方都打上日志,方便排查和定位
我截取的代码片段,为了篇幅原因,有些逻辑判断和日志处理都给摘掉,但是日志管理是很重要的一环,在关键地方打印日志,在之后排查问题和分析问题会有帮助。不然如果懒得打印日志,在关键的地方没有打印日志,即便出现了问题,也不知道从何查起,导致问题迟迟无法暴露,造成用户的投诉,那就得不偿失了。
由于个人技术有限,如果有理解不到位或者错误的地方,请留下评论,我会根据朋友们的建议进行修正
spring-analysis-note 码云 Gitee 地址
spring-analysis-note Github 地址
传送门:
参考资料
Spring 源码深度解析 / 郝佳编著. – 北京 : 人民邮电出版社