
- 背景介绍
- 深圳蚂蚁
- 微众银行
- 一面
- 1、先做个简单自我介绍吧
- 2、HashMap 怎么实现的?是线程安全的么?要线程安全怎么办?ConcurrentHashMap 怎么实现?
- 3、ThreadLocal 了解么?如果子线程想拿到父线程的上下文怎么实现?如果线程池里面的线程再创建子线程的话,怎么传递上下文?
- 4、Volatile 听说过么?Synchronized 和 ReentrantLock 实现机制如何?
- 5、双亲委派机制了解么?同名类能同时运行么?
- 6、数据库用的是什么?Innodb 特性有哪些?索引机制?
- 7、Spring Bean 生命周期了解么?Bean 实例化后,如何做一些个性化操作?如何解决循环依赖的问题?
- 8、事务隔离级别了解么?代码中事务管理怎么做的?事务传播机制考察
- 8、多线程参数含义?假如是耗 CPU 计算资源的任务,如何设置参数?
- 9、分布式系统中,如何生成全局唯一 ID?
- 二面
- 三面
- 四面
- 一面
- Shopee
- 总结
- 参考地址
背景介绍
又是好久没有静下心来总结,趁着五一假期结束,慢慢写点文字,来记录一下今年人生中一次重要的分叉口选择吧。我呢,是广东人,在广州度过了大学前的求学经历,大学去了杭州念书,也就顺势在杭州实习和工作,毕业刚开始时,还是觉得很有盼头的,努努力学习和工作,有机会能在杭州买房定居,在老东家能够学习到很多东西,无论是业务知识,还是框架的知识,都能够深入扩展学习,而且大家对我也很好,十分照顾我,也没有强制加班,整体氛围感觉到很舒适。
但一个人还是感觉到压力,工资涨幅没能跟上房价,而且家里人见面也经常会喊我回去,广东这边的广州、深圳都是一线大城市,机会也很多,建议我回来,所以在多重因数下,今年三月份的时候,开始投递深圳的岗位。
本次春招总共投了三个,分别是以下几个:
- 深圳蚂蚁
- 微众银行
- Shopee
深圳蚂蚁
这一次面试,是深圳的阿里朋友宽哥推荐的,他们团队缺人,于是内推了我,于是开始了阿里的面试之旅。
一面
一面是在 1 月下旬进行的,面试官先让我简单自我介绍了,放松一些后,就开始进入正题,回忆一下当时的面试题。
1、用的比较多的是哪些数据结构?
先简单说了下 List、Set 和 Map 这三个数据结构,接着说 ArrayList、HashSet 和 HashMap 这三者的使用方式,慢慢引出线程安全的问题,HashMap 和 ConcurrentHashMap 的区别,简单说了下源码中的细节和设计思路,面试官觉得差不多了,接着问下一题。
2、线程池有使用过的吧?说下构造参数的含义吧
这也是基础知识点,当然工作中也经常有使用到,讲了 coreSize、maxSize、keepAliveTime、blockingQueue、threadFactory 和 rejectHandler。
介绍了一下这些含义后,面试官还问到:
【阻塞队列一般用的是哪个,其它几个有了解过么】
这块之前专门有去了解过,于是介绍了 Executors.newFixedThreadPool 中常用到的 LinkedBlockingQueue,接着还说了 Array、Delay、Priority、Synchronous 这几个阻塞队列的特性,主要看 Executos 这个工具类,不同的构造器,初始化使用的阻塞队列有差别,例如定时任务线程池 scheduleThreadPool,使用到的 DelayQueue 这个延迟队列。
问到多线程后,就会有多线程下的并发问题,于是面试官开始问下一个问题
3、多线程下有遇到什么问题么?
思考了一会后,说了一下之前遇到过线程池饱满,无法处理新请求的问题,还有多线程下,想要在线程上下文中透传信息,普通的公共变量不能用,而是使用了 threadLocal,与线程绑定到一起。于是自然引出下一个问题。
4、ThreadLocal 是怎样实现的呢?
翻阅 ThreadLocal 的源码,就能知道有 ThreadLocalMap 这个内部类,ThreadLocal 更像是封装了 ThreadLocalMap 的使用。
从 ThreadLocal 的 get() 和 set(T) 方法来看,key 是当前线程,通过 Thread.currentThread() 获取当前线程后,使用 getMap(thread) 获取访问该线程的 ThreadLocalMap 对象,变量名为 threadLocals。
所以简单来说,threadLocal 内部维护了一个 map 结构,key 是当前线程,value 是 Object 类型的对象,不同线程获取到的 value 是跟当前线程绑定的,以此实现线程隔离的效果。
【恩,挺好的,那问下一个问题】
5、JVM 里的内存分布有了解么?
这里说了一下基础的内存,堆:对象初始化分配内存的地方,栈:函数调用、保存栈帧的地方,程序计数器,方法区(1.7 以前),元空间(1.8 之后),然后简单说了下元空间的优势(只记得使用了本地内存,不占用原来堆的大小)
忘了有没有问到过垃圾回收算法,这边补充一下吧,标记-清除、复制、标记-整理、分代收集,目前生产环境正处于从 CMS 到 G1 的升级,后续基本使用 G1(garbage first)这个垃圾回收器。
6、生产上使用的架构、中间件有哪些?服务器配置如何?遇到问题怎么排查?
前两个问题就见仁见智了,例如常见的分布式知识:注册中心、服务发现和调用、分布式数据库、消息中间件、缓存组件,Spring 全家桶、ORM 框架等等,按照实际情况回答就好啦。
生产问题也遇到挺多,例如 OOM,在出现问题的服务器上,使用 jmap 命令 dump 出详细的堆信息,然后使用 MAT 工具具体分析内存分布,查看具体是哪些大对象,然后根据这些信息定位到具体的代码逻辑,先看下有没有快速解决的手段,不需要改代码发版,能让用户正常使用,如果不可以的话,就赶紧评估修复方案,交叉 review,尽快发 hotfix。
还有线程池线程耗尽,这个比较简单,可以使用 jps 命令查看当前进程中,具体线程在处理的栈信息,定位到阻塞点,曾经看到是数据库或者缓存中间件达到瓶颈,临时通过扩数据库或缓存先处理问题,后续优化代码逻辑,减少这些大数据的场景出现。
接着还说了一些 gc 日志、业务日志,区分具体是系统异常,还是业务错误,balabala 讲了挺多=-=
面试官也很耐心,没有打算我说话,中间也有问细节,互相交流。
7、Spring 的了解有多少?知道一个 Bean 的生命周期么?
说到 Spring 当然就要介绍一下它的 IoC 控制反转和 AOP 切面注入,使用了 BeanFactory 管理起所有使用到的 bean,应用启动时初始化成单例,每次调用时可以直接拿到引用,避免重复的初始化,一来方便了使用,二来减少开销;接着还有 AOP 的思想,使用切面,将通用的操作,例如日志、事务等,统一管理起来,让业务方可以更专注于写业务代码,同时减少重复代码。
Spring Bean 的生命周期也是一个基础知识点,这里不多赘述,给个网上的中文图更好理解
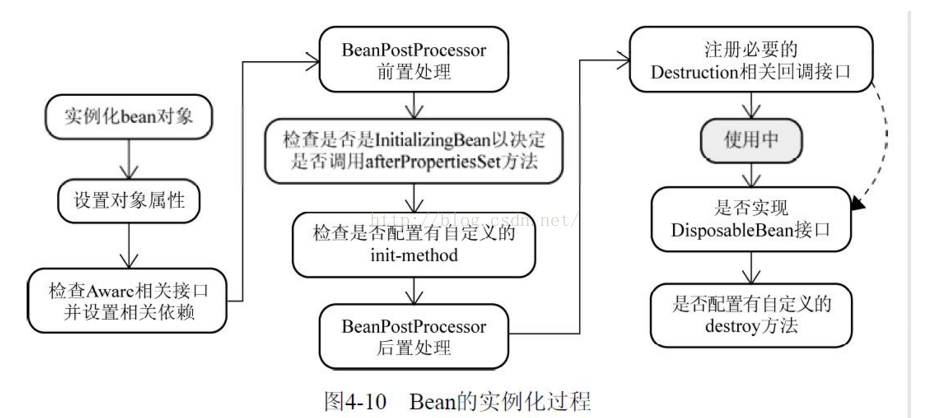
这里也跟面试官聊到,Spring 容器启动时,AbstractApplicationContext 类里面的 refresh 方法,容器启动流程所做的事情。
8、前面听你提到了 dubbo,用了其中什么特性呢?
我们使用 dubbo 来做 RPC,不同系统间通过 dubbo 来交互。具体来说,使用了 zk 作为注册中心,然后 dubbo 用来作为服务提供者 provider 和消费者 consumer。
使用 xml 形式,dubbo:provider 和 dubbo:reference 来暴露服务和订阅服务,然后说了一些常用的配置参数含义。
其中印象比较深的是官网展示的架构图,分为了十层,service、config、proxy、registry、cluster 等等,一个 bean 如何被包装成 ProviderBean 和 ReferenceBean,怎样注册到 zk 和使用 netty 启动本地端口进行监听,大致说了思路。
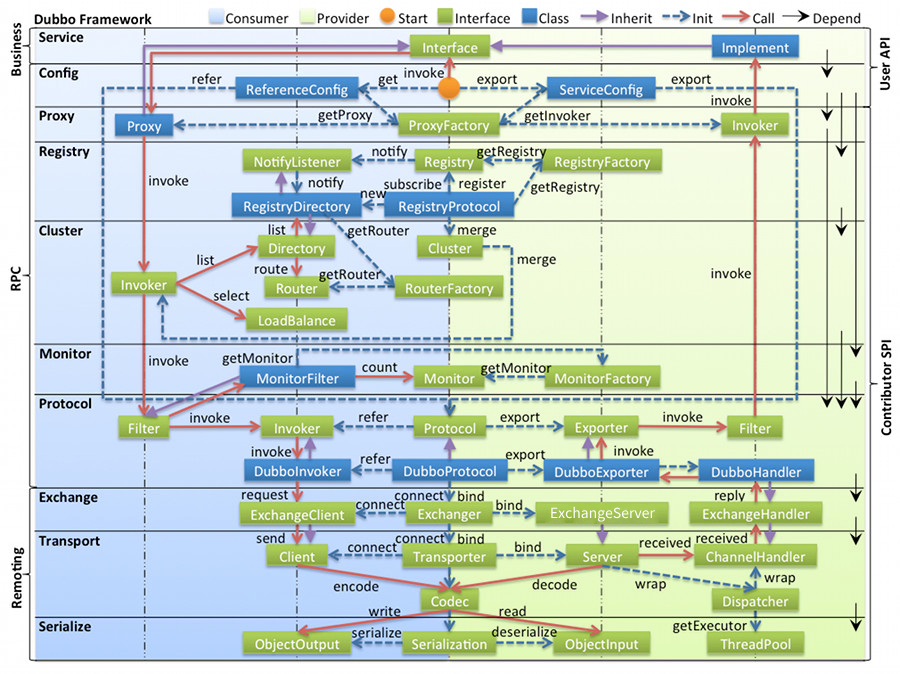
建议好好看官网的 框架设计
后面我还问了 dubbo 3.0 什么时候出,k8s 下的服务调用如何解决,他说到阿里内部有网关等相应的处理方案(有点忘了),只是看处理难易程度,总是有办法解决的。
后面想了一下,阿里人多,牛人也多,这些解决方案只会多不会少,后面再多学习学习吧。
9、数据库用的是 MySQL 么?数据量有多少?
是的,MySQL 很好用,资料也很多,我们在生产上买了阿里的 PolarDB 服务,之前叫 DRDS,分布式数据库服务,整个库逻辑表的总数据量行数有 80 亿,存储空间买了 2T * 8,也能算是数据量很大的服务体系吧。
(后面顺势问了一些 SQL 基础知识点,在之后的微众面试再细说吧)
10、之前做的项目能介绍一下么?
项目经验这边就按实介绍了业务背景和目标,然后说了自己在里面负责的模块和承担的角色,解决哪些问题和推进哪些事物等等,好好准备一下,将自己所做的事情,挑重点和有条理地说出来就好啦~
11、有什么想问我的么?
首先问了面试官,团队负责做的事项,大致整体架构和招聘进去负责哪一块的开发内容。
接着就问了一些技术上的困惑,还有关于学习建议。
挂了电话之后,看了通讯时长,50 多分钟,就这样结束一面,整体面试感受还是很不错的,面试官的语气很平和,在交流中,他会问到有些我不确定的知识点,我就提出自己的意见,然后跟他探讨是否有更好的实现方案,对方也会耐心跟我介绍他们的解决方案。
二面
等了 4、5 天吧,接到第二次面试的邀约,约在明晚进行二面,其实严格来说,应该算是 1.5 面,换了一个面试官,也是先聊了一会,然后问了两三个技术和业务问题,接着就让我在线写代码了。
1、实现一个 LRU
大家应该都了解 [least recently used](最近最少使用淘汰算法),在学操作系统的时候,了解过有这个页面置换算法,所以后面也找了时间专门看了相关资料。
网上说的方案有很多,留在我印象中的有两个
- 使用 List + Map 实现
- 使用 LinkedHashMap 实现
第一种方案中,用 List 保存 key 列表,在每次 get 和 set 或者 remove 等数据操作时,需要调整 key 在列表中的顺序,然后 Map 的操作就比较简单,用来保存 K-V。
当然这个方案实现起来有点麻烦,代码需要写很多,有些边界值也需要注意,要提升编码功力的话,也可以使用双向链表实现,但还是有点麻烦。
所以我只是跟面试官讲了一下这个思路,然后作为一个聪(lan)明(duo)的码农,我使用了现成的轮子,也就是第二种方案去实现。
第二种方案中,LinkedHashMap 可以保存访问顺序(使用链表实现顺序),并且在初始化时,设定 accessOrder=true,在数据访问和修改等操作,能自动调整顺序,以达到最近最少使用这个淘汰算法的要求
2、C,B,A 三个线程顺序启动,顺序打印 A,B,C
题目要求:不能用sleep函数,注意考虑线程安全问题。
因为之前在多线程中,就是为了利用多个线程同时并发处理不同用户的数据,也没想过保持顺序性,所以遇到这题时,思考了一会。
后面 想到了锁 Lock 和 condition 的唤醒、等待 这两个知识点
于是设想了一个这样的场景,C -> B -> A 顺序启动后,同时持有锁资源。然后 C 的下一步是去唤醒 signal B,然后 C 自己等待 await 释放掉竞争资源的锁,B 被唤醒后,重复上面的步骤,唤醒 A ,等待 A 执行结束后,唤醒 B,然后再唤醒 C。
最后输出 A -> B -> C,具体代码如下。
1 | static ReentrantLock lock = new ReentrantLock(); |
主要还是考察了 JUC 包下的工具是否了解,这一题卡壳挺久的,一开始用 synchronized 关键字,有点取巧的判断 index 执行顺序,然后倒序输出,但这样感觉有点不优雅,跟面试官讨论后,他建议再思考有没有其它并发包下的工具可以使用,于是就想到了锁和条件,尝试去实现了一下。
后来在 IDEA 中进行验证,发现方案可行,然后小改了一些,输出预期中的答案🤪
3、一道业务题
这个题目是业务场景题,我也没想到会出这样一道题目,简单说下,设计一个价格体系,计算不同商品,适配不同会员体系的折扣价。
个人感觉自己写的一般,设想是将不同【会员体系】配置成规则到数据库中,然后请求入参中带有公司 id 和用户会员等级,这样能从规则表中取出折扣规则,编码上能比较优雅。
最近在网上看到了这篇文章,题目一模一样,感兴趣的小伙伴可以看看~
全部编码完成后,面试官先看了一会,然后问了我里面的细节点,这里为什么这样写,这里的顺序有没有问题,然后还有一些命名规范上讨论了一下,总体来说也是愉快的讨论。
面试官建议我表达时再自信一点,讲出自己的想法,不用紧张(可能是当时自己没有思路,担心说错了方向,无法实现,所以比较紧张 orz)
笔试总体花了一个小时,挂了电话后,简单复盘刚才聊天内容和思路,然后就去洗洗睡了~
三面
也是过了差不多一周,收到了三面的面试邀请,这次约的时间在周六早上十点,还好平时周末也是九点左右就醒了,所以十点准时去参加视频面试。
1、先自我介绍一下吧。
2、为什么想来深圳工作?
3、简单介绍一下你做的项目吧
4、你在里面承担了什么角色
5、觉得最有挑战的地方在哪?怎么去解决的?
6、有没有什么想问的?
最后看了一下时间,总共视频了 20 分钟多一点点,在面试过程中,面试官也很随和,会针对你的回答,往下深挖,例如说到有使用消息队列解耦,他会顺着问增加了一个中间件,增加了维护成本,为什么这样选型,还有性能等等问题,上面的问题看起来比较简单,但面试官会跟你往下深挖。
所以在做需求和任务的时候,要多思考为什么要这样做,即便是别人跟你说这样去做,也可以多问问底层原因,了解利与弊,加深自己的理解,后续遇到类似的场景,就能将之前积累的经验运用上~
项目经验不会在网上细说的,毕竟是老东家的产品,但可以将其中的架构设计和技术沉淀到自身,后续有时间再梳理梳理吧。
三面结束后,因为已经 2 月,快要放假过年了…所以回家度过了两周后,才进入第四面
四面
结束春节假后,回来杭州的第一天就接到面试邀约,约在了第二天 02.20 进行视频面试。
这次遇到的 HR 是女性,自己的尴尬症又犯了,不习惯跟不熟的女生讲话,所以全程都感觉自己紧张(当然也可能跟最后一个环节面试有关=-=)
开始进入面试
1、先自我介绍一下吧。
2、为什么想来深圳工作?
3、简单介绍一下你做的项目吧
4、你在里面承担了什么角色
5、觉得最有挑战的地方在哪?怎么去解决的?
6、咨询一下您的敏感信息(结婚、薪酬流水和期望薪酬)
7、有没有什么想问的?
发现整体面试问题,跟三面老板面的框架很像,不过老板面更多关注的技术细节;HR 关注的是业务场景,问你的业务背景还有实现的价值,你对这个产品贡献有多少,会问你觉得哪里做得不够好的,怎么去改进它。
总体面了 30 分钟左右,最后我也简单问了一下学习氛围、晋升规则,还有公积金、社保等常规咨询。
就这样,结束了一次阿里面试的完整流程~
微众银行
跟微众的缘分有点奇妙,是阿里的朋友内推的,他有之前同事在微众里工作,然后觉得里面也不错,可以让我去尝试,能多一个选择项,于是就开始了面试。
一面
面试官先自我简单介绍,还有说了一下自己目前项目组负责的业务,让我有个简单的印象,接着就开始面试。
1、先做个简单自我介绍吧
2、HashMap 怎么实现的?是线程安全的么?要线程安全怎么办?ConcurrentHashMap 怎么实现?
这一题也是面试常驻嘉宾了,建议各位多去了解和熟悉。
数组加链表的设计,然后链表长度超过 8 将会转成红黑树结构,加快检索效率,HashMap 不是线程安全的,因为没有同步原语的保护,多线程可以同时操作同一个数据,有被污染的风险。
ConcurrentHashMap 在 1.7 和 1.8 的版本下的区别,分段锁设计,使用 Node 数据结构,Node 数量默认初始值是 16 个,底层使用 CAS + Synchronized 同步原语保护,不同 Node 使用不同的锁,所以大多情况下,没有 hash 冲突情况下,多个 Node 可以并发访问和操作,能够提升效率。
面试官还问到 CAS 的含义,于是就介绍了一下关键的三个值还有 unsafe 使用,在 【期望值】 == 【内存值】情况下,才将【结果值】更新到【内存值】中,常见的是 Unsafe 类中的 compareAndSwapXXX 等方法。
还有具体调用的操作系统 C 指令这些,进行自旋等待这些概念,我只说有这个概念,但具体操作系统怎么实现的,不太清楚,后续有需要的话,可以去加深学习~
3、ThreadLocal 了解么?如果子线程想拿到父线程的上下文怎么实现?如果线程池里面的线程再创建子线程的话,怎么传递上下文?
ThreadLocal 的原理前面在阿里面试的时候有介绍到,这里补充一个博客园 nullzx 博主画的图,画得很好
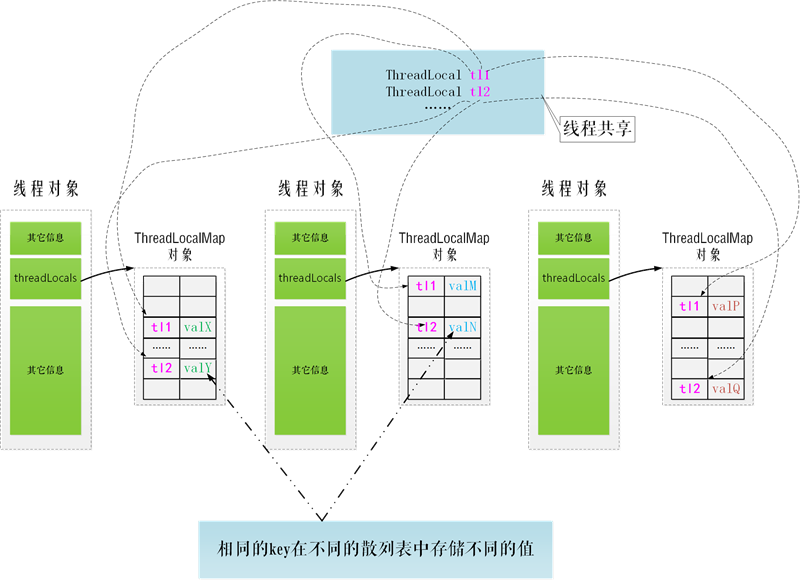
主要用来理解,每个线程都有一份自己的 ThreadLocalMap 副本,接着取出 key 类型为 threadLocal(自己创建的 ThreadLocal 对象)所对应的 value,起到线程隔离和上下文透传的作用~
在子线程中想使用父线程的上下文信息,可以使用 InheritableThreadLocal 类,当创建一个子线程时,会将父线程的上下文信息,拷贝一份到子线程中。
像是线程嵌套的场景,之前看到过阿里有介绍他们开源的 TransmittableThreadLocal,看的时间有点长,忘记了怎么实现的,而且项目中也没有实际使用的地方,于是跟面试官聊了这个概念,就诚实说自己并没有了解底层实现。
于是接着面下一题。
4、Volatile 听说过么?Synchronized 和 ReentrantLock 实现机制如何?
volatile 的作用是,每次取值都从主存中获取,保证当时的可见性一致。用这个的原因是 在 Java 的内存模型中,分成了主存和线程内的工作内存,运行时,线程会先从主存中拷贝一份数据到本地工作内存,操作之后,再往主存中写入。
在多线程情况下,一个线程修改了变量值,写入到主存中,另一个线程使用的是本地工作内存中的拷贝值,造成期望值不一致的问题。
所以加了 volatile 关键字后,每次使用都会去主存中获取,保证了可见性,避免使用本地工作内存。
同时另一个作用是防止指令重排序,避免编译器优化时,调整指令的执行顺序,可以保证在执行到 volatile 变量时,前面的操作肯定已经执行,同时后面的操作肯定没有进行。
博客园这篇文章介绍挺不错的,可以去看看 Java并发编程:volatile关键字解析
关于 Synchronized 和 ReentrantLock 的知识点,两者的区别,网上已经有很多介绍,之前也看过,所以大致介绍了锁粒度,相关 API 后,面试官问了底层实现机制,于是接着唠了 Monitor 监视器锁,反编译后的字节码,monitorenter、exist 指令;接着说了重入锁内部的 AQS 实现,使用 CLH 队列实现资源管理,还有 state 状态的管理。
回答到这个程度后,面试官也没有继续往下挖更里面的共享或独占锁,Node 节点如何出入 CLH 队列的知识点,主要考察了并发原语是否了解,然后看你了解的程度,所以这块建议多看看,结合 jdk 的源码学习。
5、双亲委派机制了解么?同名类能同时运行么?
这是一个类加载机制的问题,当时一时没想起类加载的具体名字叫啥,后来缓了一会,想起那三个类的名称。
从上往下分别是 Bootstrap ClassLoader、ExtentionClassLoader、Application ClassLoader,还有用户自定义的类加载器,一般继承 URLClassLoader,有层级关系,Bootstrap ClassLoader 是最顶级的父加载器。
然后加载类的时候,先会判断这个类有没有被加载过,加载过的话直接返回,否则进行加载流程。
加载的时候,当前类加载器会先委派父类加载器进行 loadClass,一层一层往上进行尝试加载,只有父类加载器无法加载时,才会由自己进行加载。
简书平台上 面试官:java双亲委派机制及作用,【秦时的明月夜】博主这图很清晰,有介绍每个类加载器的用途,推荐一下~
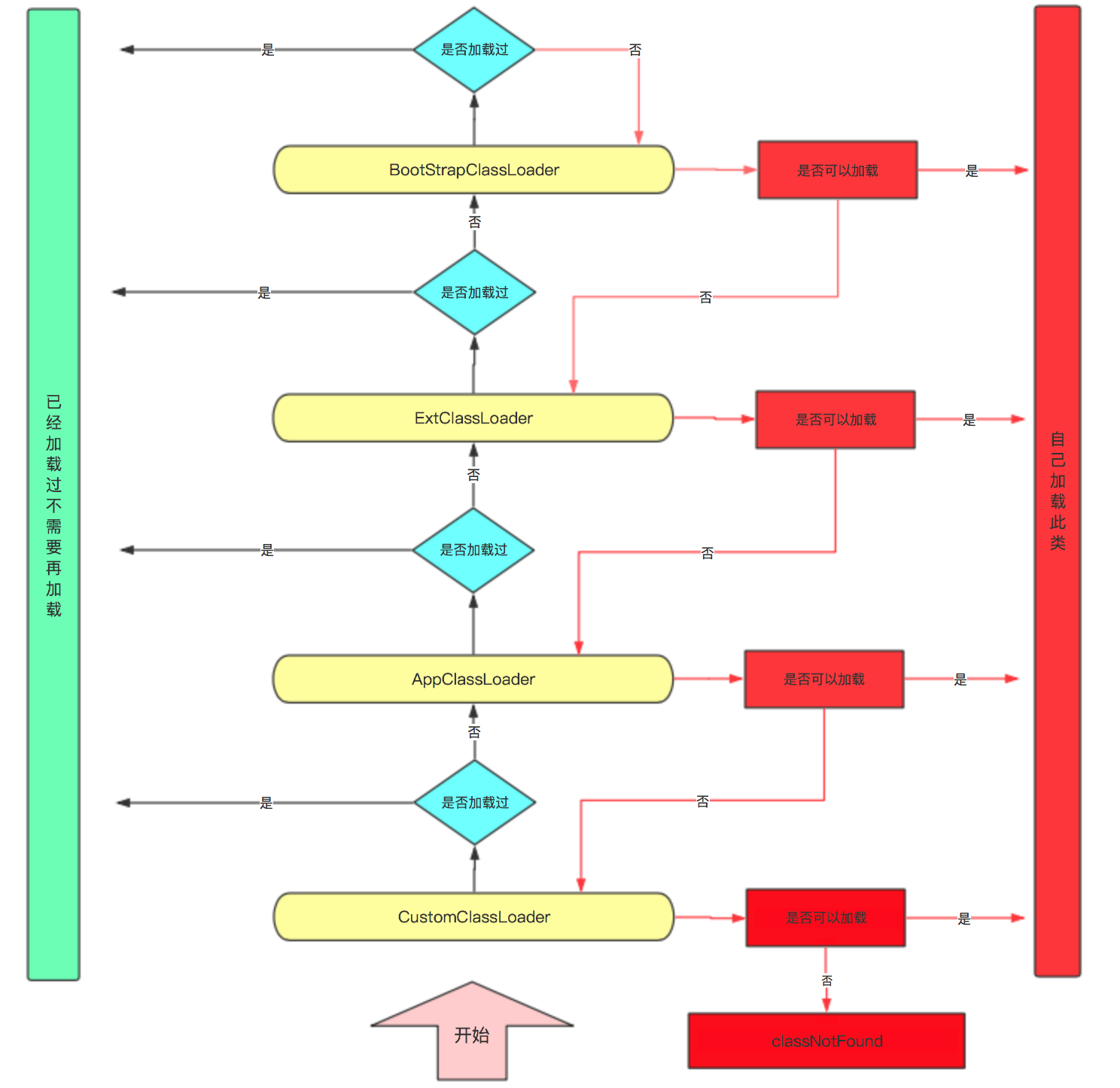
这样做的好处有两个
避免重复加载。
通过委派的形式,子类加载器不用重复加载父类加载器已经加载过的.class,节省了资源。避免安全性问题。
这个就比较值得说说,如果同时出现两个Object对象,如果能正常被加载,相当于篡改了JDK核心包的内容,所以Bootstrap ClassLoader加载过 java.lang.Object 后,后面的安全校验性规则,能够避免错误代码引起的安全性问题。
后面面试官还问到两个同名的类能否同时运行,这时想到了 判断两个类是否相同
- 类的全限定名是否一致
- 类被加载的加载器是否相同
于是回答面试官,说可以自己新建两个用户自定义类加载器,然后分别加载这两个类。
6、数据库用的是什么?Innodb 特性有哪些?索引机制?
使用的是阿里云的分布式数据库服务,底层是 MySQL。
Innodb 是默认的存储引擎,主要看中它的这几个特点:
- 比较完整的事务支持
- 有行级锁,锁资源粒度更细
- 支持外键和新版本后支持全文索引
具体哪个版本开始支持,有点忘了,查了资料,说是 5.6 之后开始支持
索引的实现数据结构是 B+ 树,然后聊了一下聚簇索引和非聚簇索引的含义和区别。
聚簇索引,也就是我们常用的主键索引,在树的结构中,叶子节点保存了完整的数据记录,所以根据主键查询,可以在聚簇索引中查询一次就获取结果;其它创建的是非聚簇索引,在这些索引上查询到主键的值,然后回表查询完整的数据域,这样需要查询了两次索引。
面试官问到:刚才说到回表,那有什么方式可以减少回表么?
接着就说到覆盖索引,例如一个表中,【a, b, c】是常用字段,这样给这三个字段创建一个联合索引,然后 select 中,只选择这个三个字段,这样从联合索引中可以直接取到查询结果,不需要回表。
后面面试官还问了 order by 跟索引字段的顺序的关联,还有模糊查询对执行计划的影响,关于 MySQL 这块,要多去了解索引实现、一些常见的查询场景还有执行计划相关的内容~
7、Spring Bean 生命周期了解么?Bean 实例化后,如何做一些个性化操作?如何解决循环依赖的问题?
Spring 的生命周期在前面聊过,重点是去看 AbstractApplicationContext 的 refresh() 方法,这个方法模板很重要,需要多去看看,这样自然就能了解 Spring 启动流程,还有 bean 初始化的步骤。
在 Spring 中,有 InitializingBean 接口,通过实现该接口,重载 afterProperties() 方法,这样就能做一些个性化操作。
循环依赖的话,Spring 中可以自动解决,前提是使用默认的 singleton 单例模式,而且不能是构造器注入。
对于 setter 注入造成的依赖可以通过 Spring 容器提前暴露刚完成构造器注入但未完成其他步骤(如 setter 注入)的 bean 来完成,而且只能解决单例作用域的 bean 依赖。
在类的加载中,核心方法 org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#doCreateBean,在这一步中有对循环依赖的校验和处理。
跟进去方法能够发现,如果 bean 是单例,并且允许循环依赖,那么可以通过提前暴露一个单例工厂方法,从而使其他 bean 能引用到,最终解决循环依赖的问题。
更多可以去看下之前整理过的知识点 Spring 源码学习(五)循环依赖
8、事务隔离级别了解么?代码中事务管理怎么做的?事务传播机制考察
这一块既考察了 MySQL 事务隔离机制,又考察了 Spring 的数据库事务管理器,还有传播机制。
隔离级别有四种:
read uncommited:读未提交read commint:读已提交repeatable read:可重复读serializable:序列化读
我们生产使用的级别是 read commited,不过现在新的数据库,推荐使用的是 repeatable read,隔离级别越高,数据保障性也就更高,但数据库支持的并发度会相应降低,所以一般使用 RC 或者 RR 就够了。
代码中,我们使用了 Spring 中的 TransactionTemplate,通过事务模板来设定具体事务管理器 DataSourceTransactionManager,还有事务传播机制 required_new,具体编码时,使用了 @Transactional 注解来开启事务。
后来面试官还问了事务失效的场景,还有方法调用间,两个不同事务传播机制,内层失败是否影响外层,外层失败会不会影响内层之类的。
8、多线程参数含义?假如是耗 CPU 计算资源的任务,如何设置参数?
多线程参数的配置参数说明,前面也说过,所以不再赘述。
一般配置线程数时,我会先参照下面的公式:
- CPU 密集型:CPU 核心数 + 1
- IO 密集型:CPU 核心数 * 2
参考过《Java 并发编程实战》书中的内容,但因为 IO 密集型时要计算的阻碍系数太麻烦,所以我一般 IO 密集型时,设置的线程数 = CPU 核心数 * 2。
当然具体使用的时候,我会根据 JVM 性能监控来判断,具体要配置多少线程,一般通过 Grafana 监控,或者本地 jvisualvm,不断调整线程数配置,将整体负载控制在 50 % 以下。
其实就是没有规定的配置方式,根据性能情况具体调整。
9、分布式系统中,如何生成全局唯一 ID?
之前有看过美团的文章,他们开源了一个 Leaf 算法,分为了 Leaf-segment 和Leaf-snowflake 方案。
不过具体实现我忘记了,只记得推特的 snowflake 雪花算法,于是跟面试官说了生成规则:

常规面完之后,问了面试官一些团队负责具体事宜,然后看了通话时间,发现已经超过 1 小时。这一次面试是时间最长,面试官问的问题都是基础题,没有过多问刁难问题,也是顺着我的回答,继续问相关的内容。
问的内容更偏向实际开发,很多要考虑的细节点。同时也帮我巩固了很多基础知识点,感谢~
二面
隔了 3、4 天,收到了二面邀约,也是选在晚上进行视频面试。
有一些基础问题,还有业务相关问题就不重复记录了,这里记录下关于 RocketMQ 相关的问题吧。
1、RocketMQ 的架构如何?
主要有四个模块,producer、consumer、namesrv 和 broker。
生产者的启动类是 DefaultMQProducer,在发送消息时,先从 namesrv 获取 topic 的路由信息,了解要发往哪些 broker,并与 broker 建立连接,关于网络通讯,底层使用的是 Netty 框架,创建了 Channel 通道,然后根据 selector 选择器,默认是轮询算法,遍历 queue,往指定的 broker 进行发送消息。
broker 是消息存储的地方,它的存储机制比较有意思,将消息内容保存进文件时,使用了 Linux 的 mmap 技术,还有顺序写,避免随机写的性能差。
存储文件有这些目录,consumequeue、index 和 commitlog,前两个存储的是消息消费进度和方便检索消息的索引,commitlog 就是存储完整消息的文件,使用了顺序写。
消费者的启动类是 DefaultMQPushConsumer,是的,这里的消息 push 推送,采用的是主动拉取方式,消费者启动定时线程池,默认隔 1s 往 broker 拉取消息。
还有更多关于限流和负载均衡的内容没有细说,面试官就问下一题。
2、RocketMQ 发送消息后,如何保证两个系统的一致性?
其实这题考察的是分布式事务,而 RMQ 作为可靠消息中间件,同时在金融领域也普遍应用,也有自己一套事务保证机制。
具体事务消息机制:
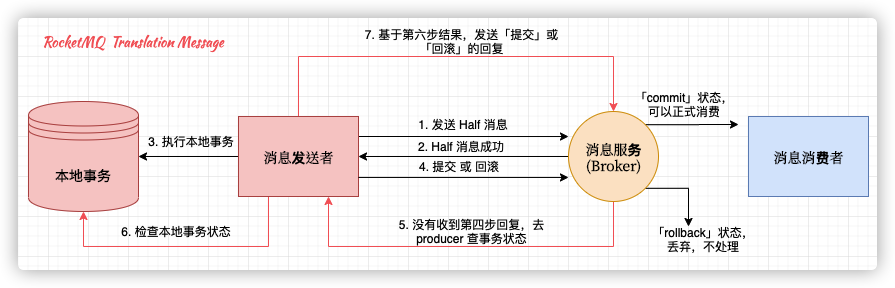
主要分为两个流程:
- 正常消息的发送、提交
(1)producer发送Half消息
(2)broker本地写入Half消息(将Topic改成RMQ_SYS_TRANS_HALF_TOPIC,该阶段Consumer由于没有订阅关系,无法消费)
(3)producer根据broker写入消息结果,成功的话,执行本地事务;写入消息失败,producer不执行本地事务
(4) 根据本地事务结果,往broker发送Commit或者Rollback(如果是Commit,将会将Half消息转回Real Topic,生成消息索引,订阅者可以进行消费) - 补偿流程:
(1) 半消息发送成功,但broker没收到Commit或Rollback,进行状态回查(上图的第五步)
(2)Producer收到回查消息,检查本地事务状态
(3) 根据本地事务状态,重新发送Commit或者Rollback
补偿阶段用于解决消息Commit或者Rollback发送超时或者失败的情况
当然在回答的时候,没有回答这么详细,简单说了整个流程就没继续问了。
后面就是跟面试官聊了一些业务相关的内容,看了一下总体时间,在 30 分钟内,这一面考察了更多关于 RMQ 的细节。
三面
同样,也是隔了三四天就约了三面时间。
这次是部门经理面试,主要问的是项目经验,承担什么角色,还有关于自己,对未来职业的规划。
部门经理很有威严感,我在回答的时候有点战战兢兢,后面也是跟他聊了一下,如果自己能进,具体要做哪块业务,未来成长空间如何等。
结束后看了一下时间,20 分钟,可以说是相当快的流程。
四面
这次等了将近一周,收到四面邀请,HR 约的时间是早上,没有晚上的时间,所以那天向公司请了一天事假=-=
这次 HR 面,更多是跟我介绍他们所做的事情,办公地点还有薪资、各种福利之类的。
整个过程更像是聊天,结束后看了一下时间,20 分钟多一点点,也是很快的流程了。
四个流程下来,微众这边的面试流程也完成了。一二面考察技术和项目经验,观察个人的技术功底如何,三四面考察团队契合度,还有个人的成长潜力。
总体来说,微众这边的面试很考察基础,不会刻意刁难,所以基本功要扎实,整体面试过程体验感很 Nice。
Shopee
Shopee,中文名是虾皮,也被称做虾厂,是做东南亚电商的一家外企。
跟它的缘分也很巧妙,也是听别人说深圳除了腾讯外,虾皮的薪酬和工作强度都很不错,在深圳来说,属于性价比极高的一家公司,于是顺手投递了一份简历。
从收到面试邀约,一周内就结束三轮面试流程,面试官的主语言应该是 Python 或 Go,所以问的 Java 内容并不多,更多考察计算机的基础,例如网络、select poll epoll 的优缺点、分库分表的设计,还有方案设定的依据是什么。
这里记录一下一二面中,给我留下比较深印象的问题吧:
1、Netty 有使用过么?对它了解多少呢?
一想到 Netty, 就想到它的线程模型,回答了 Recator 模型,还有启动时用的 ServerBootstrap,负责处理 I/O 连接的 bossGroup 和处理具体业务的 workGroup,简单来说,Netty 使用了多路分发技术,其中有 acceptor 接收请求,然后交给一组 NIO 线程池 bossGroup 进行网络 I/O 读写,进行消息的编解码,接着将消息传给另一个 NIO 线程池 workGroup 进行业务处理。通过多路复用和良好的主从 Recator 多线程模式,达到高并发高性能的要求。
主要 Netty 还处在初步使用阶段,没有深入去挖源码实现细节,所以当时回答时有点班门弄斧,有点不确定满意程度,后续需要加强 Netty 的细节学习。
2、分库分表设计的依据是什么?
数据量大了之后,使用分库分表是一件很正常的处理方案,当时回答了,按照数据增长量,按照每张表阈值 5000w 的评估,设定成 8 库 8 表。
后来面试官深挖,每个表的阈值怎么确定的,还有如何能这么准确评估出数据增强量。诚实回答按团队规范去操作,由于的确没去了解当时分库分表策略,在工作中自然而然使用了之前定下的规范,导致对一直在用的方案不熟悉。
所以这也给我提了一个警醒,需要去深入了解项目中使用的方案,为什么这样选型,依据是什么,有什么优劣,只有掌握细节,才不会被技术细节所坑。
3、服务器规模如何?系统并发量多少?具体性能如何?
现在推崇的是微服务架构,所以按照领域拆分了很多细小服务,单独部署。
当时回答了服务器的规格,还有几个核心服务,部署了多少个,但 TPS 和 QPS 却不敢准确回复,因为自己的确没有很关注具体数值,只在监控平台上看过范围值,所以回答的时候不够自信。
其实面试官也是在考察你对自己系统是否足够熟悉,能否准确评估资源使用,还有对性能的敏感程度。所以后续工作上,需要更多关注自己维护的系统,尽量做到高性能还有熟悉用户使用量。
其它类型的问题跟前面说过的有重复,所以不再赘述啦。虾皮的效率十分快速,一周内就结束面试流程,同时面试官也很年轻,感觉虾皮是一个年轻化的公司,十分 open 和务实,整体感受十分良好。
总结
于是乎,21 年的春招就这样结束了。
其实我已经跟老东家提了离职,有很多很多不舍,所以再来聊下我的老东家吧
我在老东家,从 17 年到 21 年,大三下学期就开始实习,实习一年后,拿到毕业证顺利转正。在这里的氛围很 nice,有同龄人的愉快玩耍,也有成熟稳重的前辈带领,所以在这边的工作环境真的觉得还是挺不错的。
同样,这边很多同事都是阿里、网易之类大厂过来的,技术能力和工作能力都不错,从他们身上也能学到很多东西。加上我两个师傅都超级厉害,有不懂的问题都能给我解释清楚,在他们的带领下,学习到很多知识,成长的速度很快。
而且这边每周三有篮球俱乐部的活动,那天快到六点时,三五好友一起约着去打球,在球场上冲撞,挥洒汗水 (怎么突然感觉在演青春剧(゚Д゚) ),刚好当时三四月,也陆陆续续有朋友离职,每打一场球就送别一位球友,那段时间,打完球就找个烧烤店闲聊,好好道了个别。

感觉遇到的每个人都很好,给我帮助很多,人际交往很融洽,工作上也给了很大自由度,虽然也有业务目标的要求,但更多会考虑工作安排合理性,而且也能自己提出技术需求,在做业务需求的同时,也能增强自己的技术,领导也十分赞成这种方式,培养人才。
这几年时间,获得过一些荣誉,所负责的业务可以独当一面(小夸一下),也能带领新人,跟着成哥和小王爷学到很多很多,有相应的技术沉淀。
总之总之,其实对老东家还是挺不舍的,但薪酬的确跟外面少,而且杭州离广州的确还是有点距离的。所以过年的时候,就确定今年要回广东的计划。
人呀,有时候是需要跳出舒适区,有个朋友也跟我说,「未来你还会遇到这种场景」,所以一下子就释然了。

(上面是周末刚做的晚饭,各位也要记得按时吃饭~)
接下来的规划,工作上也要继续努力,有更多东西需要学习,有很多基础需要继续夯实,要多去锻炼身体,周末尽量自己做饭吃,如果有时间的话,要去学一门乐器,尽量做到工作和生活的平衡。
感谢各位小伙伴能看到最后,送上迟到的新年祝福,祝各位平安喜乐,万事胜意~